
.png)


AI summarization tools have come a long way, but most still struggle with a familiar set of problems: inconsistent accuracy, generic output, and slow performance that breaks the flow of work in high-volume sales and support settings.
These issues aren't the result of weak models. They stem from shallow context, mismatched data, and architectures that aren’t built for the realities of the contact center.
This paper outlines how Cresta takes a fundamentally different approach, one designed from the ground up to deliver summaries that are fast, tailored, and grounded in your actual operations.
Each section highlights the key components of that system. We’ll walk through the pipeline, including what happens at each stage, why it matters for your team, and how it all connects.
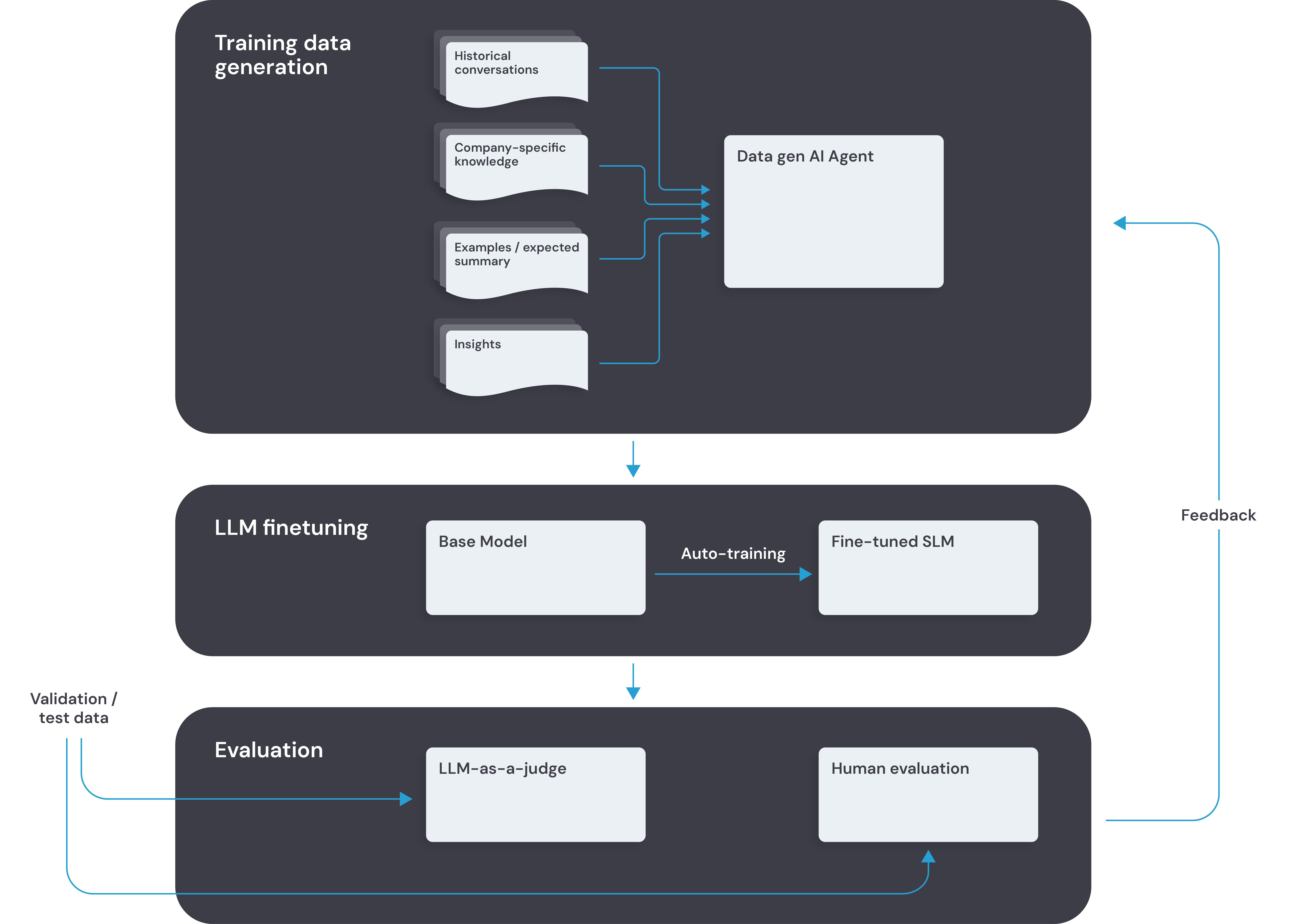
1. Building domain-aware training data
Why this matters: Generic LLM prompts won’t capture your company’s unique language or reliably align summaries to domain-specific use cases. Cresta uses a “Data-Generation Agent” to automatically synthesize examples that reflect your business’ call topics, workflows, policies, and terminology.
Core inputs:
- Recorded calls, complete with speaker turns and outcomes
- Your organization’s jargon, policies, main call reasons, and flow diagrams
- Sample summaries that define tone and scope
- Metrics on frequent issues and resolutions
Rather than hand-labeling hundreds of calls, the data-generation agent plans its work, analyzes your knowledge and data, generates data, then reviews and refines its summaries until they meet internal quality checks.
The result: a large, laser-focused training set.
2. Fine-tuning for speed and cost, without sacrificing quality
Why this matters: You can’t run a multi-step AI agent in the heat of a live call. It’s simply too slow and compute-heavy. Instead, Cresta distills that sophistication into a slimmed-down model by:
- Applying instruction-based fine-tuning to an SLM base model using the generated dataset, with careful hyper-parameter tuning and sampling strategies
- Using reinforcement learning to align the model with reward functions like factuality, completeness, and brevity
With the new compact model, Cresta reproduces the agent’s quality, while achieving the latency and cost profile required for production workloads.
3. Keeping quality on track, even in edge cases
Why this matters: Even a well-trained model can drift over time or miss unusual scenarios. Cresta ensures ongoing accuracy through automated and human checks.
- Automated judging: a separate LLM scores each summary against held-out validation data, spotting deviations from expected behavior
- Human spot-checks: subject-matter experts review borderline cases and flag subtle errors or missed nuances
- Closed-loop feedback: scores and audit findings feed back into the agentic data generator, refining future training sets
By combining machine and human oversight, Cresta prevents quality degradation and continuously sharpens summary performance.
4. Speeding up inference for AHT reduction and live note-taking
Why this matters: Summaries need to be generated in seconds to maximize AHT reduction, or update continuously to truly replace note-taking in regulated industries. To further reduce latency, Cresta combines:
- Dynamic batching: multiple requests share a single GPU pass without adding extra delay per query
- Model quantization: reduces memory footprint and increases throughput while maintaining summary quality
- Flexible delivery modes: summaries can generate continuously throughout a live conversation or within a few seconds of its conclusion
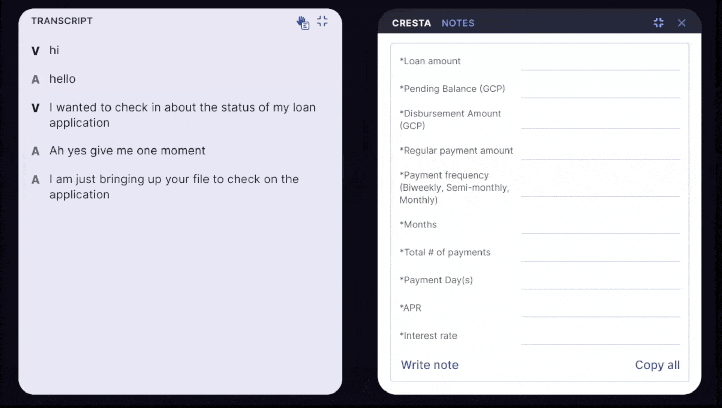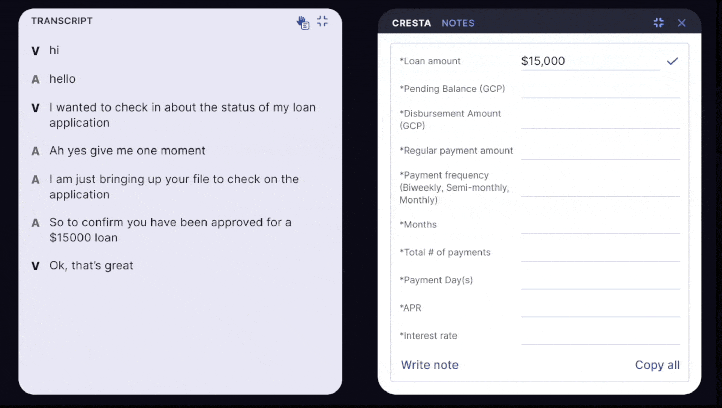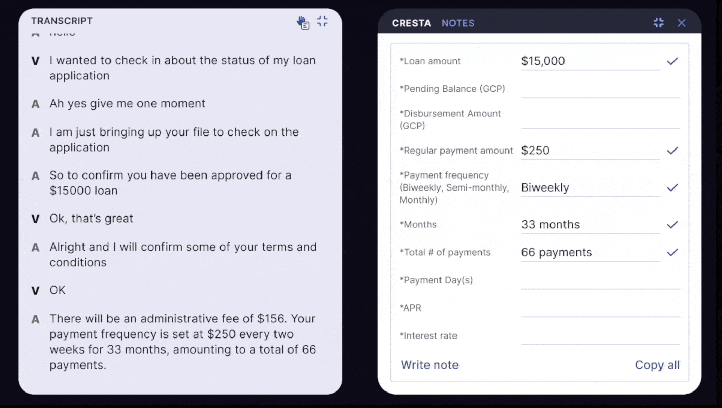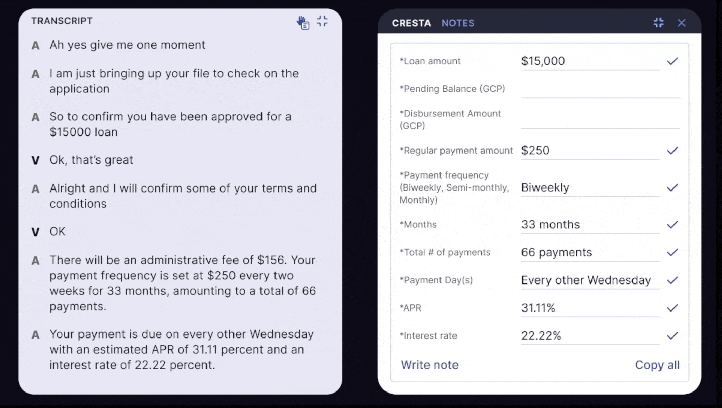
These optimizations cut both cost and latency, while offering distinct modalities to help organizations better support the needs of their business, without making unnecessary trade-offs.
5. Customization Without the Risk
Why this matters: Tailoring summaries to highlight specific details can accidentally degrade other fields. Cresta’s customization flow prevents that by isolating changes and enforcing consistency:
- Two customization tracks
- Structured fields (dates, amounts) follow a schema-driven pipeline that validates format and values
- Descriptive topics (call reasons, next steps) use a flexible text-generation pipeline tuned for style and completeness
- Structured fields (dates, amounts) follow a schema-driven pipeline that validates format and values
- Isolated edits
- Customer Engineers adjust examples for one topic (e.g. payment date) without touching others
- Unrelated topics remain locked, ensuring no unintended drift
- Customer Engineers adjust examples for one topic (e.g. payment date) without touching others
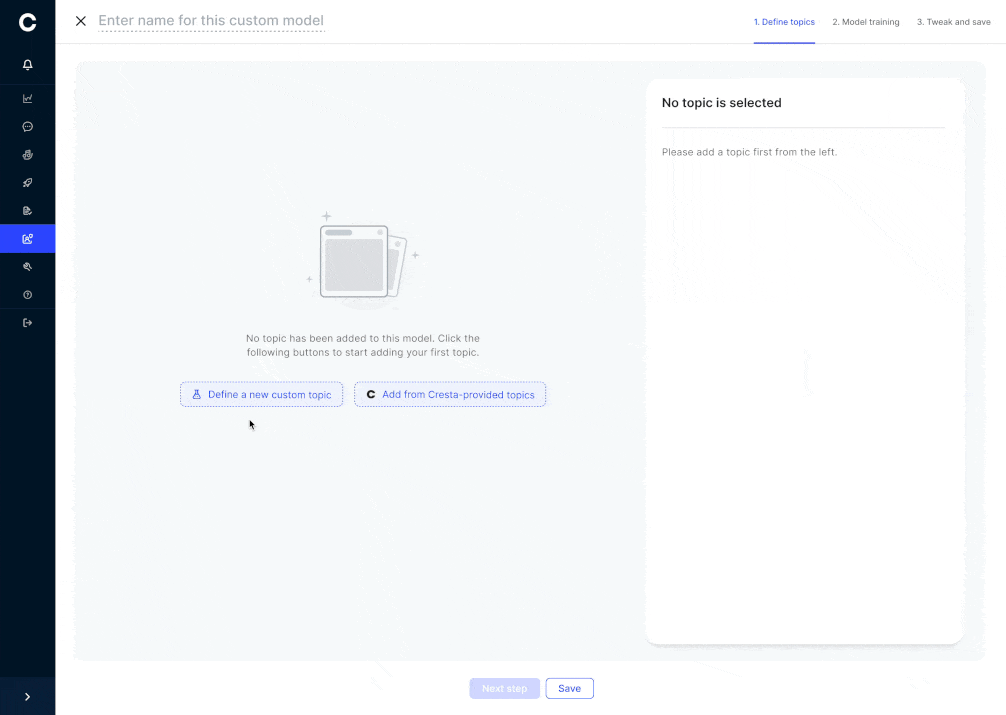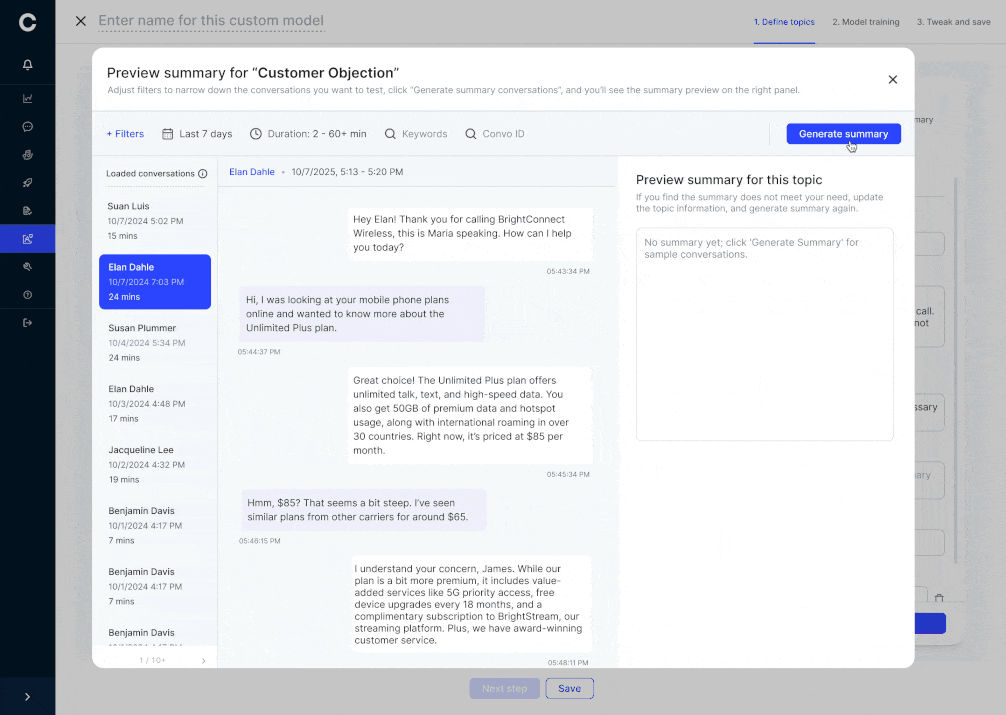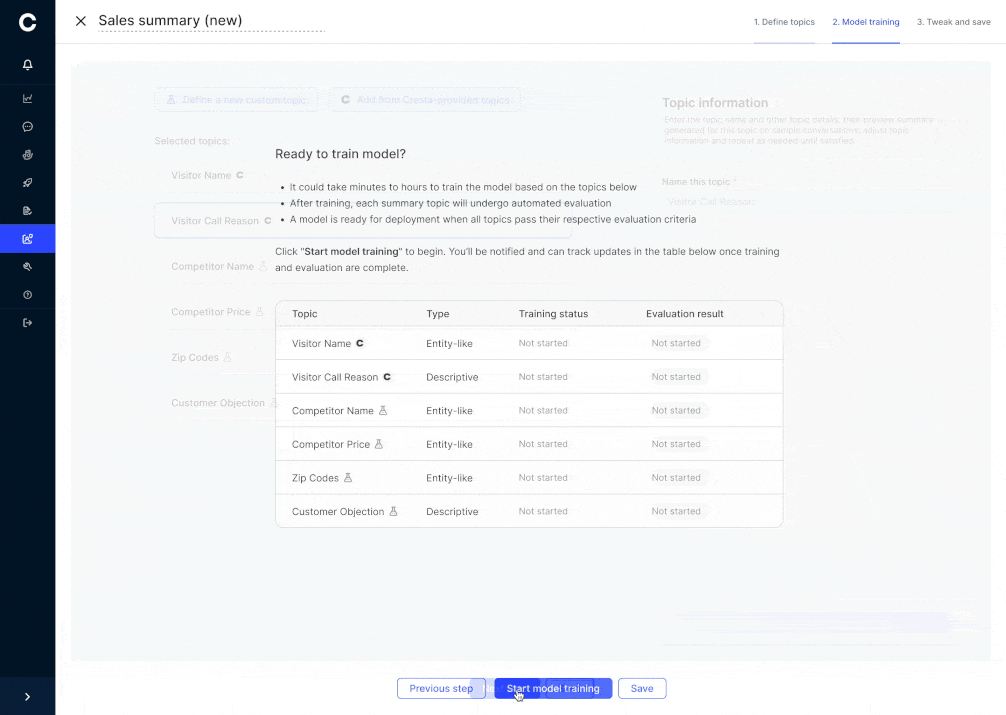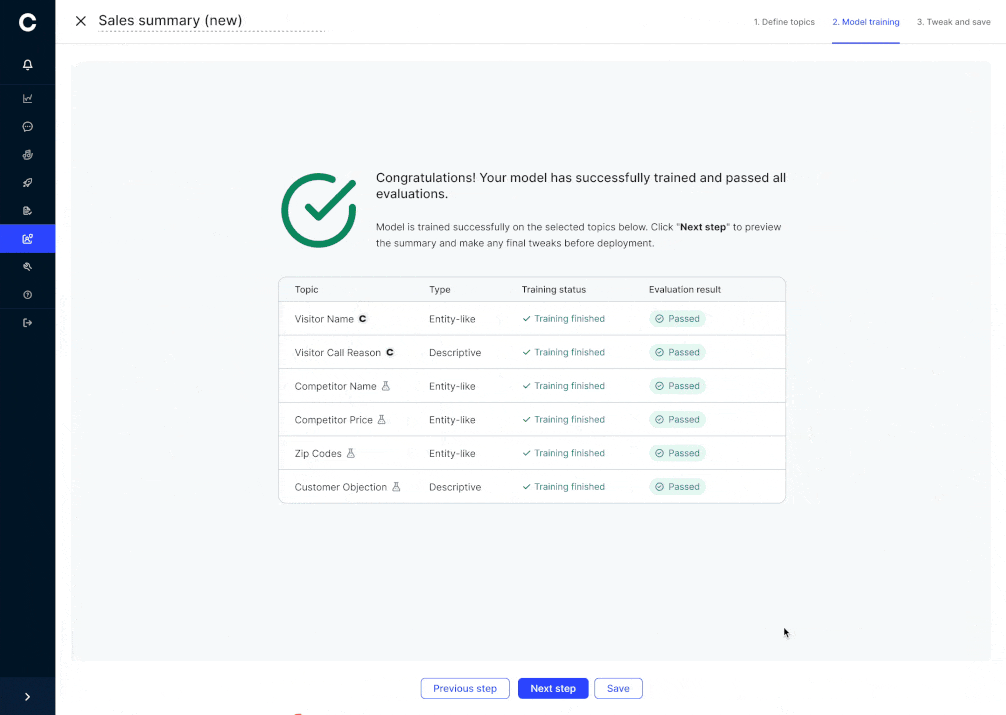
This approach delivers fine-grained control through an intuitive UI while keeping the overall model behavior stable and reliable.
6. Supporting Advanced Call Flows
Why this matters: Complex contact center scenarios involving multiple speakers or transfers between teams can pose unique summarization challenges:
- Multiple speakers within one call: when multiple agents join a single call (e.g., conferencing or joint troubleshooting), summarization needs can vary based on who is actually speaking in different contexts. Some topics, such as individual action items, require clear attribution to each speaker. Others, like overall call reasons or key issues discussed, should remain speaker-neutral.
Cresta supports these scenarios through configurable settings, allowing each topic to be marked as speaker-aware or speaker-agnostic. This enables the model to dynamically include speaker-role information only where needed, ensuring summaries are clear yet concise. - Transfers across multiple call legs: Transfers across departments or escalation tiers require context from multiple conversations. Cresta solves two distinct challenges:
- Latency between transfers: Cresta can proactively generate earlier summaries using techniques like speculative decoding, ensuring summaries are ready even if transfers occur rapidly.
- Exceeding model input limits: Cresta chains related call legs together, with the ability to incrementally summarize each leg and feed each component into the final call summary. This approach maintains comprehensive context without sacrificing speed or accuracy.
- Latency between transfers: Cresta can proactively generate earlier summaries using techniques like speculative decoding, ensuring summaries are ready even if transfers occur rapidly.
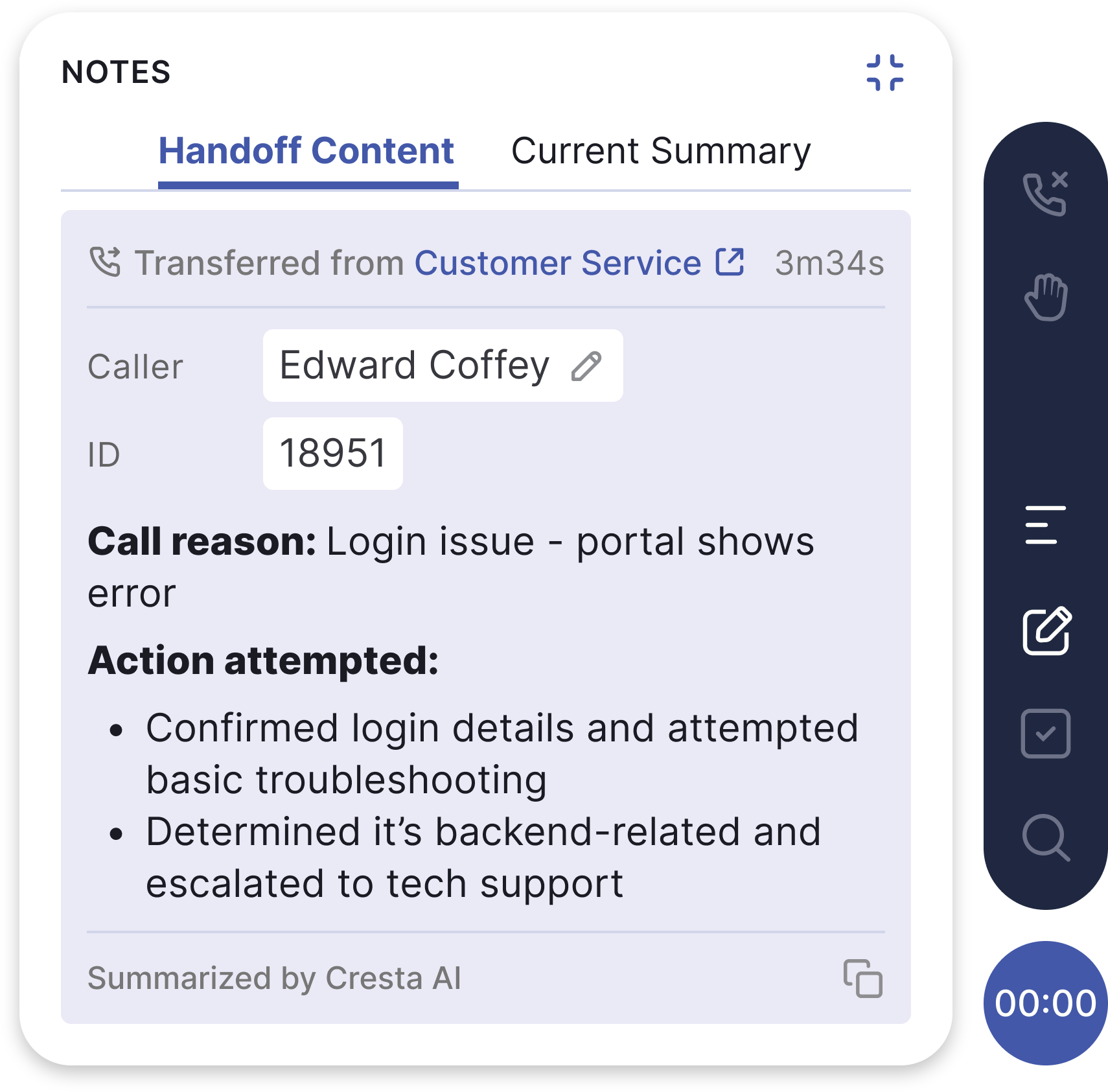
High-quality summaries shouldn’t require tradeoffs between speed, reliability, and flexibility. Cresta’s architecture is designed to avoid those compromises, leveraging agent-generated data, targeted fine-tuning, and optimized infrastructure to deliver fast, accurate summaries tailored to the needs of each unique business.




